
Table of Contents
Introduction
Database normalization is the process of structuring data into a solid relational database schema. By solid I mean that the structure is efficient and effective, redundancy reduced and integrity improved. The normalization process usually takes place alongside the process of creating an Entity Relationship Diagram, or ERD for short.
The Process
If you want a more in-depth reasoning about why you would want to normalize a database structure, I recommend reading the sources in the references at the bottom of the page or find more information elsewhere about it.
Instead of explaining each Normal Form (1NF, 2NF, etc) in detail, I will translate a software product description from structural chaos into BCNF: Boyce-Codd Normal Form.
Product Description
Let’s assume this simple fictional description:
The “Ticket System” is an application where users of Company X can report IT related incidents. These incidents can be about either hardware or software. Submitting a ticket goes via a web portal where the user enters the following information: physical location, personal information, information about of software or hardware, problem description, steps to reproduce the problem, attachments and whether status updates (push notifications) are desirable. All hard- and software of the company should be inventoried.
Authenticated employees who are assigned to an incident can further categorize and prioritize an incident and give a status to it. It is also possible to filter the ticket list based on priority and status. Messages can be added to the ticket, with the choice of it being a private (internal) message or a public message which is also readable by the reporter. Everything the employee will add or edit about the ticket is kept track of by the system.
The system administrator can manage employee authorizations and assign a role. It is possible to create reports about response times, time to repair and number of incidents.
Interpreting the Description
We can extract verbs and nouns from the text.
| Verbs | Nouns |
| Report, Submit, Enter Information, Reproduce, Authenticate, Deal, Categorize, Prioritize, Give Status, Filter List, To Assign, To Add Message, Add Information, Edit Ticket, Track, Add/Edit Solution, Manage/Authorize Employees, Create Rapport | Ticket System, Application, Users, Company, Incident, Hardware, Software, Ticket, Web Portal, Physical Location, Personal Information, Problem Description, Problem, Attachment, Status, Updates, Notifications, Inventory, Employees, Messages, Articles, Reporter, Administrator, Role, Rapport |
Although a framework like ITIL distinguishes between incidents and problems, in this example I will throw it all on one pile. All the nouns are candidates for database tables or attributes. All verbs may describe the relationships between them. I did not find this directly in different sources I read, but I remember this to be a mnemonic to help defining entities and relationships. If we would make each noun a table, we can roughly see that as our 0NF or the first step at creating the ERD.
Note that some things are not mentioned in the description but could be part of the data to normalize. For instance, if we were to make a hardware table, we might add separate tables for certain hardware parts like CPU and GPU. Other pieces of data might be otiose.
A Collection of Data (0NF/UNF)
Entity or Attribute
An entity is represented by a database table. An entity is usually something like a person, place, object or concept that you want to store. An attribute is a field of the entity. If you can answer two of the following questions with yes, it is likely that the noun should be its own table.
- Do you want to store multiple of it?
- Does it have its own identity? (e.g. id, serial)
- Does it have a lifecycle? (e.g. a status you want to keep track of?)
- Does it have its own attributes? (e.g. author, date, or other fields)
- Does it get referenced by other entities?
- Do you want to keep track of changes or history?
Processing Nouns
With table 1 (the verbs and nouns) as starting point, I made the following decisions:
- I omit Ticket System and Application as entities, because they are implicit, this is what we are building.
- The system has or should support multiple users; thus, we need a users table.
- Each user needs to authenticate with the system. We assume with authentication comes certain privileges. We will define these privileges as permissions, which are based on certain roles in the system.
- Company might be implicit, the company that is currently using the application we are about to build, but if you want to be able to manage and distinguish between multiple companies, we might add it as an entity.
- We have hardware and software as topics where the reported incidents will be about.
- In our case tickets, incidents, and problems all refer to the same thing. We’ll go with tickets. Description and status are part of that, therefore those could be defined as attributes later.
- Attachments could be kept as a separate entity.
- The web portal is how we will access our application. This is not going to be an entity to store data about.
- The physical location is part of the ticket but could also be part of the company. We’ll regard it as attribute for now.
- Personal information belongs to the users entity.
- Messages are added to tickets.
- We omit notifications (for now) because they will likely be emails.
- Furthermore, rapports could be fabricated out of the data we have about tickets. There might be a reason to make a table out of it, but we’ll also decide later.
Interim Result
If you design data models more often, you will most likely develop some sort of intuition on how to structure data. I honestly had a hard time to throw down the data as is, without automatically removing some redundancies.
To keep the example of the process as simple as possible, I will start small. From the processed nouns I have created these two tables:
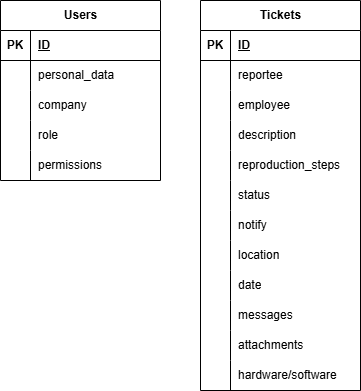
Users and Tickets have become their own tables, the metadata below are attributes so far.
Records & Fake Data
A record is one entry in a table. So, if we would add a user to the Users table, that would be called a (new) record in the table. Using actual data (real or mock) to populate the tables with, could help to determine flaws and will make abstract rules more concrete as the same time. I would surely recommend using it if it’s available.
| ID | personal_data | company | role | permissions |
| 1 | John Doe, address, phone | company x | administator | can update, can delete, can create, can read |
As we filled this in, we can already see that the attributes personal data and permissions contain non-atomic data, we’ll fix that later.
Relationship Multiplicity
During the normalization process we not only have to figure out what becomes a table and what becomes an attribute, but also what the multiplicity of the relationship between entities will be:
| Multiplicity | Description | Example |
| 1-to-1 (1:1) | One record of an entity belongs to exactly one record of another entity. | Each user has one role exactly |
| 1-to-many (1:N) | One record can hold many references to another entity. | Each ticket can have multiple messages |
| many-to-many (N:M) | Each record of one table can hold many references to records of another table and vice versa. | Each role can have multiple permissions, and each permission can be attached to multiple roles. |
| No relationship | A table has no relationship with other tables | This could be a table with something like system logs. |
Important sidenote: a database can be configured to have 0-to-1, or 0-to-many relationships. In this case the Foreign Key might be empty. For instance, when a ticket has just been created, it could be the case that no employee is yet assigned. Therefore, the employee_user_id attribute could then contain a null value.
To 1NF
We’ll continue with the diagram with tables from image 1.
Rules to Get to 1NF
- Each record can be identified by a primary key.
- No repeating groups or arrays
- Atomic attributes, or in other words: indivisible values
Processing the Data
Basically, we can go over all attributes and ask ourselves the same questions as in the Entity or Attribute chapter. I made the following decisions:
- All tables (in our example) already have a primary key (PK): ID.
- Personal_data in the users table is non-atomic and needs to be split up to multiple attributes.
- A user can have more than one permission, therefore it should become a separate table.
- Each ticket can have multiple messages, therefore it should become a separate table.
- There can be multiple attachments and should therefore also should become a separate table.
- Hardware and Software is not a single data type.
Avoid Repeating Groups
To be clear, even if you suspect a ticket would never get more than three attachments, we must avoid creating a table with three attachment fields as a repeating group, like:
| Ticket | ||||
| ID | Description | Attachment_1 | Attachment_2 | Attachment_3 |
Interim result 2
After following the rules we’ll get the following tables:
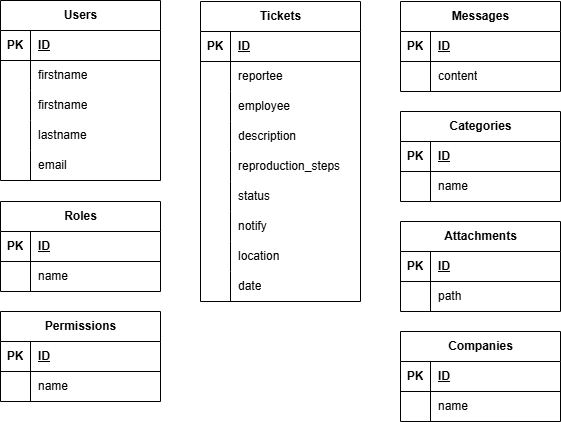
To 2NF
As stated in other sources, the second normal form is based on the concept of fully functional dependency. This means that each attribute of a table depends on the full primary key. So far this is still the case, because all our tables have a single primary key.
Rules to Get to 2NF
- Eliminate partial dependencies
Processing the Data
In our case we should create a many-to-many relationship with roles and permissions. Let’s say we have four permissions for tickets, create, read, update and delete. And let’s say we have three roles: administrator, employee, and reporter. Each role can have read_ticket as permission, and the read ticket_permission belongs to each role as well. The edit_ticket permission would likely only belong to an employee and administrator and not to a reporter.
Implementation of a link (or pivot) table
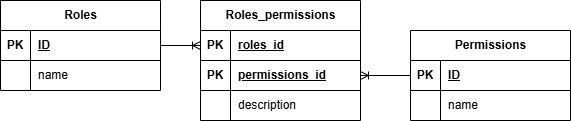
The roles_permissions table is a combination of the primary keys of a role and a permission. As long as the description attribute is dependent on the whole primary key, which is both roles_id and permissions_id combined, the design is in 2NF. A correct description would be something like: Administrator may delete tickets.
Example of A Wrong Implementation of 2NF
If an attribute in the roles_permissions table would only depend on one part of the primary key, it would violate 2NF. An example would be attributes like permission_description and role_description separately because each would then only depend on one part of the primary key. E.g. permission_description would depend on permissions_id.
To reach 2NF, each attribute must depend on the full primary key, everywhere in the design.
Interim Result 3
With each 1-to-many (or 1-to-zero-or-more) relationship between entities, the Foreign Key (FK) is always in the table of the “many” side of the relationship, the one with the crow’s foot line ending. For instance, each attachment belongs to 1 ticket, and each ticket has 0 or more attachments. Textual descriptions are not required in ERDs.
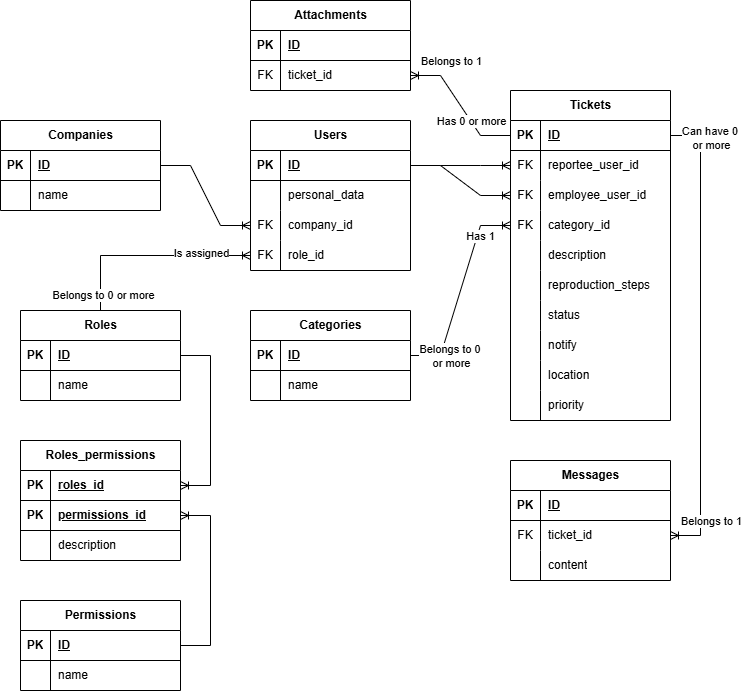
To 3NF
Let’s introduce an issue with our design. Let’s imagine that the company the ticket system will be designed for has three physical locations where one location is the headquarters. An important stakeholder of the project has decided that tickets that report an incident at the headquarters should automatically have a higher priority. This is an example of a business rule, which is usually a policy, guideline, or constraint that governs how data is handled or how processes are operated. In this hypothetical situation the ticket priority is thus determined by the location attribute. In this case the attribute “priority” is dependent on the “location” attribute. This is a violation of 3NF.
Rules to get to 3NF
- There is no transitive dependency for non-prime attributes. This means a non-key attribute may not be dependent on another non-key attribute.
- A table is in 3NF if every non-key attribute depends only on the primary key.
Solving the Problem
There are multiple ways to solve this issue. The priority could have been a calculated field that will be corrected with some logic that will take the location into consideration. By removing the priority as attribute, the problem is solved. Although, by removing it, we cannot easily sort tickets by priority anymore.
A parallel problem is that it is not clear what is meant with the attribute “location” after all, which was described as physical location in the product description. Is it supposed to be an office, an address, a workplace? A combination of these?
Let’s assume the stakeholder decided that a ticket must be linked to a physical workplace and that the priority would be derived from that. Even when the priority is calculated dynamically (and still saved in the database) with location as factor, it is still considered a violation of 3NF for the same reason as stated before.
Interim Result 4
Two extra tables have been added, one for Workplaces and one for Priorities. Both workplace_id and priority_id in the tickets table are not non-key attributes. This removes the transitive dependency between location and priority.
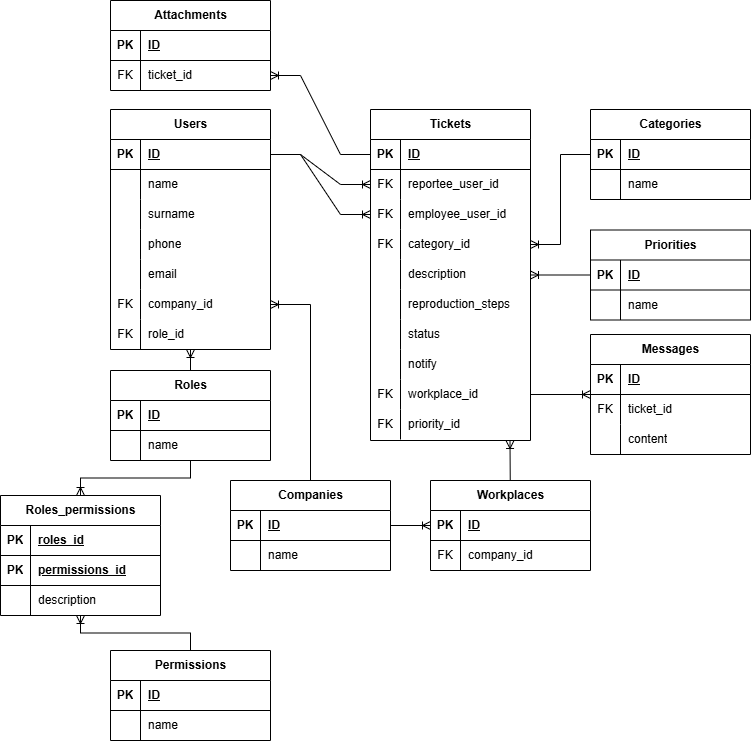
To Boyce-Codd Normal Form (BCNF)
A functional dependency in database design is a relationship between two attributes or sets of attributes in a table. Formally, this is written as X → Y, meaning that X determines Y. Here, X is called the determinant attribute(s) and Y the dependent attribute(s).
A superkey is a set of one or more attributes that can uniquely identify every record in a table. A candidate key is a minimal superkey. The primary key is one chosen candidate key. In our case, almost all tables have (or will have) an auto incremented integer as primary key. Therefore, we did not contemplate so much about what the primary key of a table should be so far.
Rules to get to BCNF
- Every determinant must be a superkey.
Added Features
We can again introduce one or more business rules that needs us to alter our design as the current design should already be in BCNF. It is that same stakeholder that is pressing the issue that “management” needs to know the lead time for each ticket, as well as when it was submitted. They also want each incident to be able to be scheduled for repairs or fixing, with an estimated end date so they can know what employee is busy or not. Because a repair may require a person to come to the physical location, more information is need.
First design
Let’s design this step by step. We’ve created a new table called Ticket_Schedule that does not have an auto increment integer as primary key this time. We have a combination of ticket_id and repair_date as primary key.
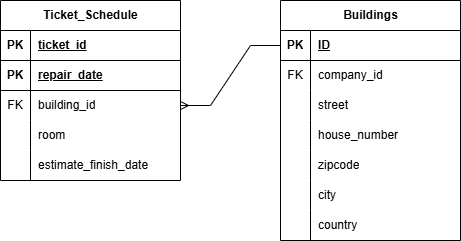
The BCNF Violation
At first glance this looks okay, but the devil is in the details. Image that the company has a strict rule that each room has a global unique identifier, even over multiple buildings. We can conclude the following:
- The room attribute is a non-key attribute, while building_id is not.
- The room attribute is not a superkey, because on itself it does not identify a row in the table.
- The room attribute does identify building_id because we know each room is unique and belongs to a building.
- Room determines building, while room is a determinant and thus this violates BCNF.
The Solution
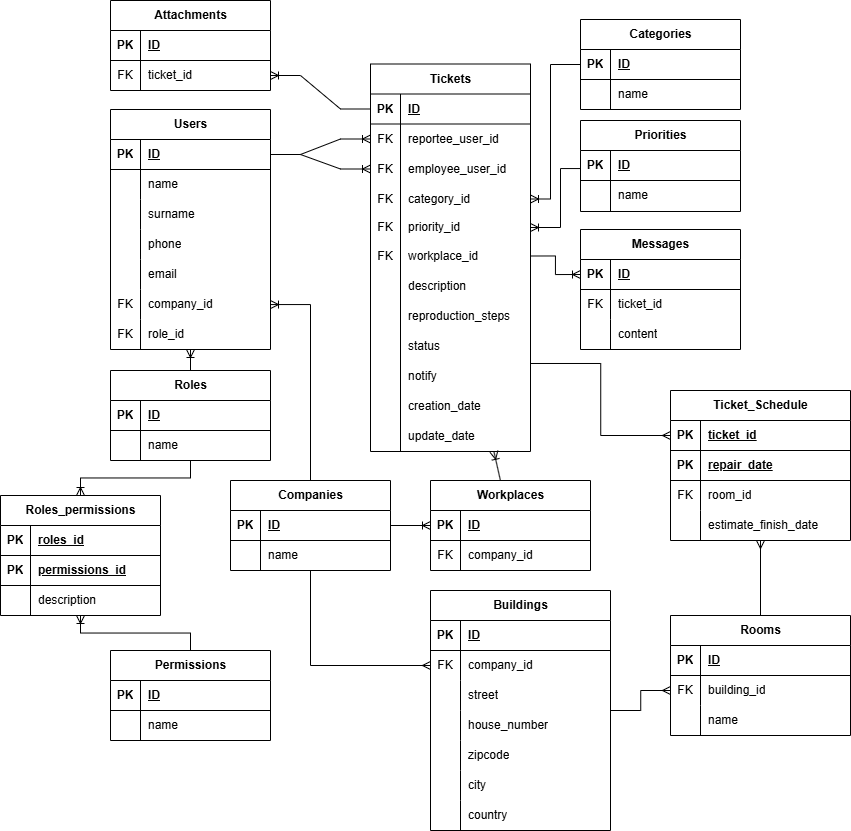
The Tickets_Schedule table does not have a direct relationship with Buildings anymore, but with Rooms instead.
Conclusion
We created a database design from description to BCNF. For me, it has been a while since the last time I progressively build up a design from scratch like this. This post is merely an example, tables like Companies and Rooms should probably have more attributes. If you see anything that’s wrong or missing, be sure to send me a message through the contact form.
References
Baranwal, V. (2025, 27 juli). Database Normalization: 1NF, 2NF, 3NF & BCNF Examples. https://www.digitalocean.com/community/tutorials/database-normalization
GeeksforGeeks. (2025, 9 oktober). Introduction to Database Normalization. GeeksforGeeks. https://www.geeksforgeeks.org/dbms/introduction-of-database-normalization/
Wikipedia contributors. (2025, 2 september). Database normalization. Wikipedia. https://en.wikipedia.org/wiki/Database_normalization

